Deploy models faster, run workloads efficiently, and scale seamlessly with our state-of-the-art GPU infrastructure designed for AI researchers, startups, and enterprises.
Eliminate infrastructure complexity and focus on what matters most — building exceptional AI applications.
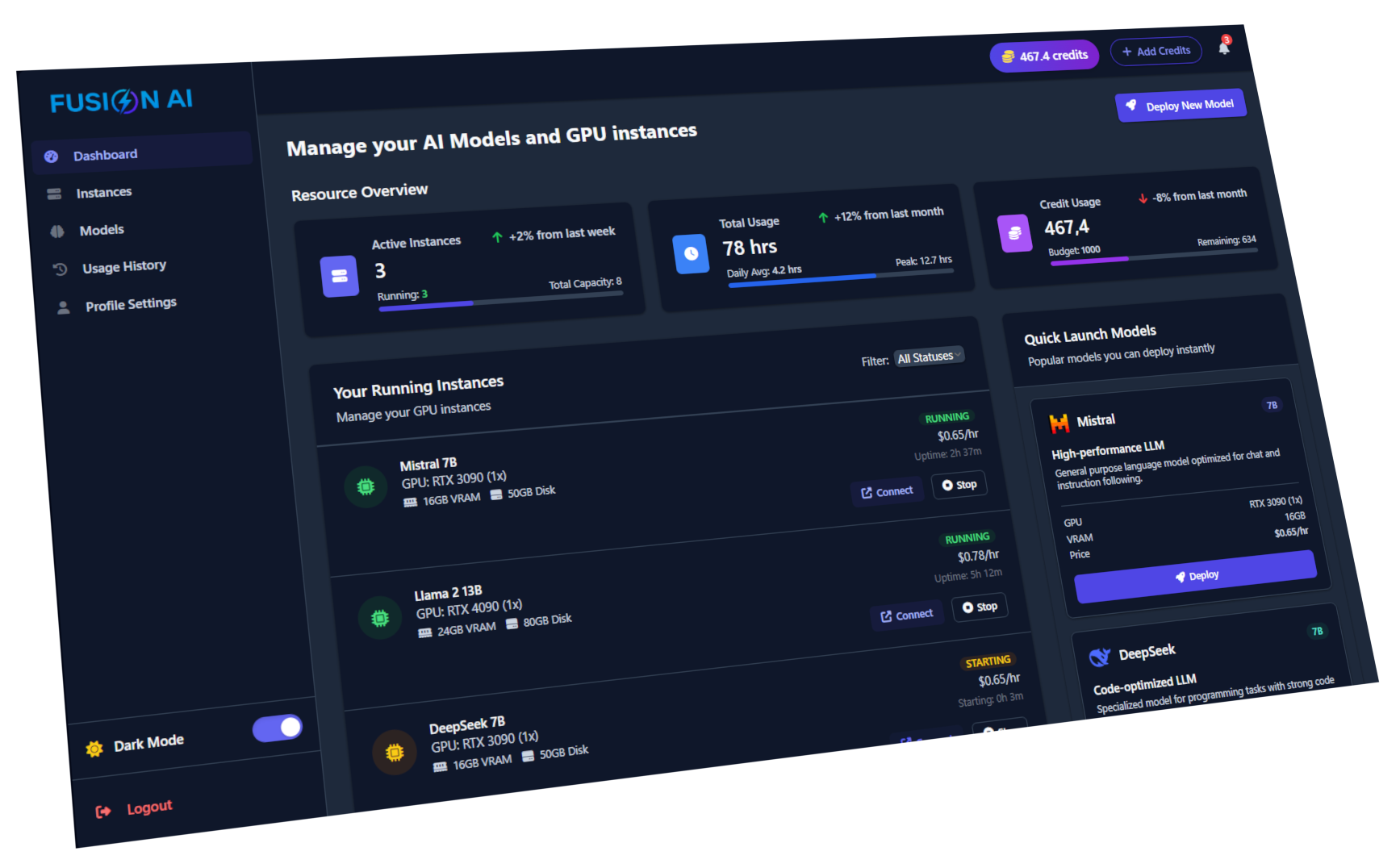
Access NVIDIA H100, A100, and other high-performance GPUs without the capital investment. Pay only for what you use.
Deploy AI models with a single click. Our platform handles the infrastructure so you can focus on innovation.
Your models and data remain private. Deploy in isolated environments with enterprise-grade security and compliance.
Built-in tools for team collaboration. Share access, manage resources, and work together efficiently on AI projects.
Full support for PyTorch, TensorFlow, JAX, and other popular ML frameworks. Bring your code, we handle the rest.
Up to 70% less expensive than major cloud providers. Only pay for the compute you actually use with transparent pricing.
Access the most in-demand AI models with no token limitations. Full control, complete privacy, and lightning-fast deployment.
Deploy and run DeepSeek R1, a powerful general-purpose model with state-of-the-art reasoning capabilities.
Run Llama models in your private environment with complete control over settings and output.
Deploy Google's lightweight but powerful Gemma models for efficient inference and specialized tasks.
Deploy the cutting-edge QWQ models with full parameter access and customization options.
Run Mistral AI's efficient and powerful models with industry-leading performance per parameter.
Upload your own fine-tuned models. Full support for all major frameworks including PyTorch, TensorFlow, and JAX.
Join WaitlistSelect from popular open-source models or upload your custom fine-tuned model
Set your GPU allocation, scaling preferences, and deployment region
Click deploy and your model is online in minutes with a private API endpoint
Access the latest NVIDIA GPUs without the capital investment. Our platform offers a range of GPU options to meet your specific AI workload requirements.

Pay only for what you use with no hidden fees. Up to 70% more affordable than major cloud providers.
All instances include unlimited bandwidth, storage billed separately at $0.05/GB/month. Sustained usage discounts available.
Competitor prices as of April 2025. All prices reflect on-demand hourly rates. Fusion AI prices include basic storage and networking features.
Hear from researchers and enterprises who've already been granted early access to our platform.



Find answers to commonly asked questions about our platform and services.
We're currently serving selected enterprises, research labs, and universities. Join our waitlist to get access when we open to the public on April 23, 2025.